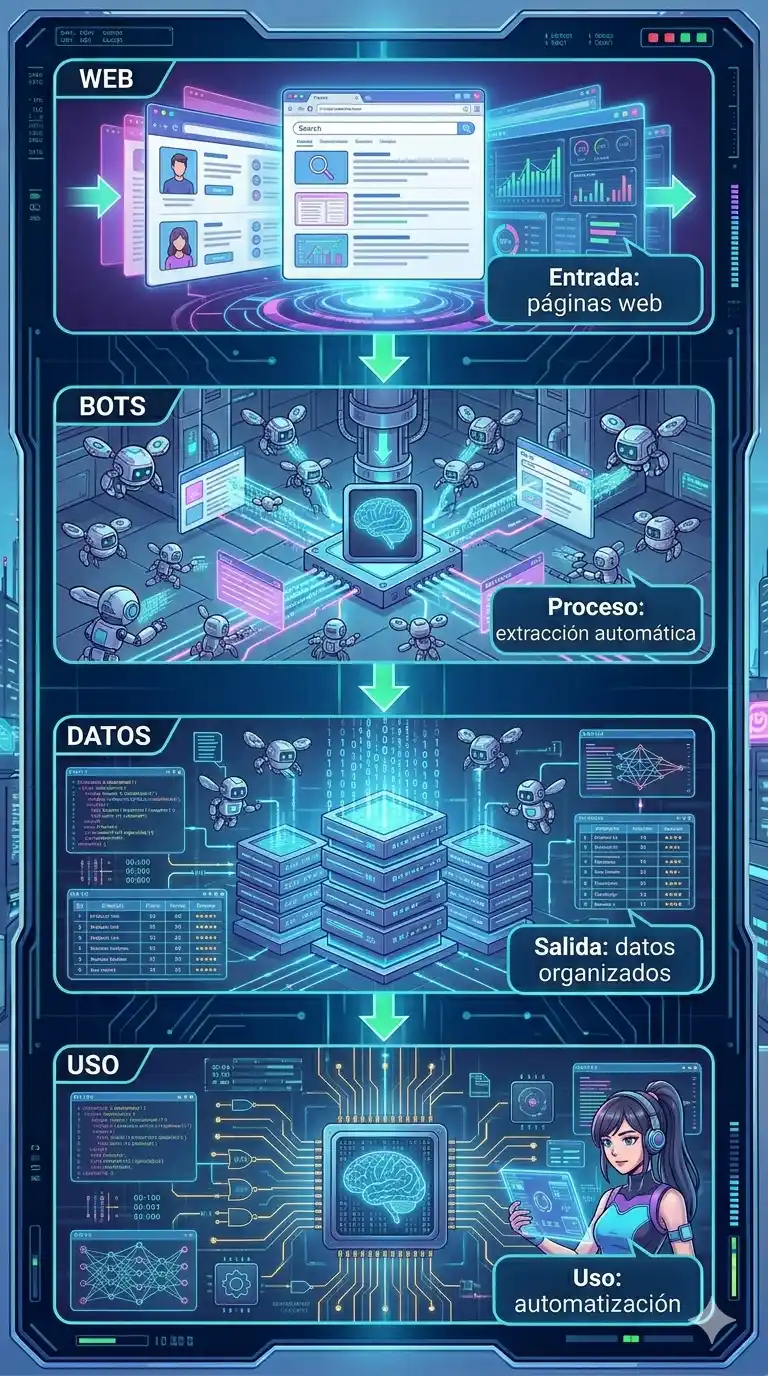
El Web Scraping y la Automatización Web son técnicas utilizadas para interactuar con sitios web de forma programática, sustituyendo la navegación manual por procesos ejecutados por software. Aunque están estrechamente relacionados, cumplen funciones distintas.
1. Web Scraping: Extracción de Datos
El Web Scraping es la técnica de extraer información específica de sitios web para convertir datos no estructurados (HTML) en datos estructurados (como una base de datos o un archivo Excel).
- Cómo funciona: Un script (bot) envía una solicitud HTTP a una URL, descarga el código HTML de la página y luego «parsea» (analiza) ese código para extraer los elementos deseados, como precios, títulos o nombres.
- Casos de uso comunes:
- Comparación de precios: Monitorear el costo de un producto en Amazon, eBay y otras tiendas.
- Generación de leads: Extraer información de contacto de directorios de empresas.
- Análisis de sentimientos: Recopilar miles de comentarios de redes sociales para saber qué opina la gente de una marca.
2. Automatización Web: Acción y Navegación
La Automatización Web consiste en programar un software para que realice tareas repetitivas en un navegador tal como lo haría un humano. No solo lee datos, sino que «actúa».
- Cómo funciona: Se utilizan controladores (drivers) que abren un navegador real o «headless» (sin interfaz visual) y ejecutan comandos como hacer clic, escribir en formularios, hacer scroll o resolver captchas.
- Casos de uso comunes:
- Pruebas de software (QA): Verificar automáticamente que el botón de «Comprar» de una web funcione después de cada actualización.
- Publicación de contenido: Automatizar el posteo en múltiples redes sociales simultáneamente.
- Llenado de formularios: Completar registros masivos o trámites burocráticos repetitivos.
3. Diferencias Clave
| Característica | Web Scraping | Automatización Web |
| Objetivo Principal | Obtener información. | Ejecutar una tarea o flujo de trabajo. |
| Interacción | Generalmente pasiva (solo lectura). | Activa (clics, escritura, navegación). |
| Resultado | Un dataset (CSV, JSON, SQL). | El cumplimiento de una acción (ej. un pedido hecho). |
| Herramientas | BeautifulSoup, Scrapy. | Selenium, Playwright, Puppeteer. |
4. Consideraciones Éticas y Legales
Es vital recordar que estas prácticas deben realizarse con responsabilidad:
- Robots.txt: Es un archivo en la raíz de los sitios web que indica qué partes pueden ser rastreadas y cuáles no. Ignorarlo puede resultar en el bloqueo de tu dirección IP.
- Términos de Servicio: Muchos sitios prohíben explícitamente el scraping en sus contratos de uso.
- Límites de velocidad: Realizar miles de peticiones por segundo puede ser interpretado como un ataque de denegación de servicio (DDoS). Un buen desarrollador siempre implementa retardos entre peticiones.