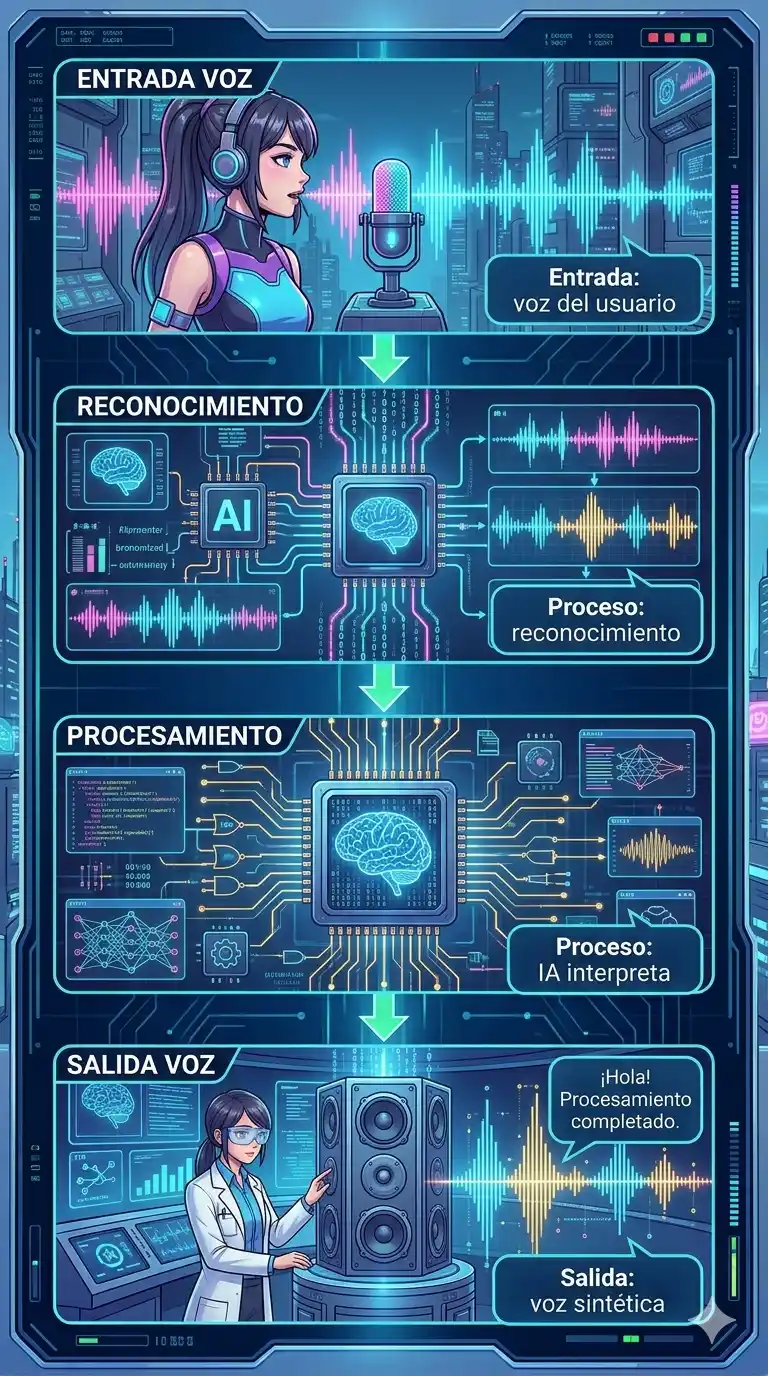
El reconocimiento y la síntesis de voz son las dos caras de la moneda en la comunicación entre humanos y máquinas a través del lenguaje hablado. Ambas tecnologías se basan hoy en día en redes neuronales profundas para lograr una naturalidad casi humana.
1. Reconocimiento de Voz (ASR – Automatic Speech Recognition)
Es la capacidad de una IA para procesar ondas sonoras, identificar las palabras y convertirlas en texto digital. Su función es «escuchar» y «entender».
- Cómo funciona:
- Procesamiento de señal: El audio analógico se convierte en digital y se eliminan ruidos de fondo.
- Extracción de características: Se fragmenta el audio en unidades mínimas de sonido llamadas fonemas.
- Modelado de lenguaje: La IA utiliza modelos estadísticos para predecir qué palabras tienen más sentido según el contexto (por ejemplo, diferenciar «valla» de «vaya»).
- Aplicaciones: Dictado de mensajes, subtitulado automático en tiempo real y comandos para asistentes virtuales (Siri, Alexa).
2. Síntesis de Voz (TTS – Text-to-Speech)
Es el proceso inverso: la IA recibe un texto escrito y lo convierte en audio hablado. Su función es «hablar».
- Evolución técnica:
- Concatenativa: Antiguamente se unían fragmentos de grabaciones reales (sonaba robótico).
- Neuronal (Neural TTS): Actualmente, las redes neuronales aprenden las variaciones de entonación, ritmo y énfasis de un locutor real. Esto permite que la voz tenga prosodia (emoción y naturalidad).
- Clonación de voz: Una rama avanzada donde la IA solo necesita unos segundos de una muestra real para replicar el timbre y estilo de una persona específica.
- Aplicaciones: Narración de audiolibros, voces de GPS y accesibilidad para personas con discapacidades visuales.
Diferencias Clave
| Característica | Reconocimiento (ASR) | Síntesis (TTS) |
| Entrada | Audio (Voz) | Texto |
| Salida | Texto / Comandos | Audio (Voz) |
| Desafío principal | Filtrar ruido y entender acentos. | Lograr entonación y emoción natural. |
| Objetivo | Comprensión. | Comunicación / Expresión. |
La intersección: IA Conversacional
Cuando combinas estas dos tecnologías con un LLM (Modelo de Lenguaje Grande como Gemini), obtienes un sistema capaz de escuchar, razonar una respuesta y responder hablando de vuelta en milisegundos, cerrando el ciclo de una conversación fluida.