La Inteligencia Artificial en el procesamiento del lenguaje se divide en dos áreas fundamentales que trabajan en conjunto: el Procesamiento de Lenguaje Natural (NLP) y la Traducción Automática (MT). Su objetivo es que las máquinas no solo «lean» texto, sino que comprendan el contexto, la intención y las sutilezas culturales.
1. Procesamiento de Lenguaje Natural (NLP)
El NLP es la rama de la IA que permite a las computadoras entender, interpretar y generar lenguaje humano. A diferencia de la programación tradicional, donde las reglas son rígidas, el NLP utiliza modelos estadísticos y redes neuronales para manejar la ambigüedad del habla.
Componentes clave:
- Tokenización: Dividir el texto en unidades más pequeñas (palabras o subpalabras).
- Análisis de Sentimiento: Determinar la carga emocional de un texto.
- Reconocimiento de Entidades (NER): Identificar nombres propios, fechas o lugares.
- Modelos de Lenguaje (LLMs): Como los que alimentan a los asistentes actuales, entrenados con billones de parámetros para predecir la siguiente palabra en una secuencia.
2. Traducción Automática (Machine Translation)
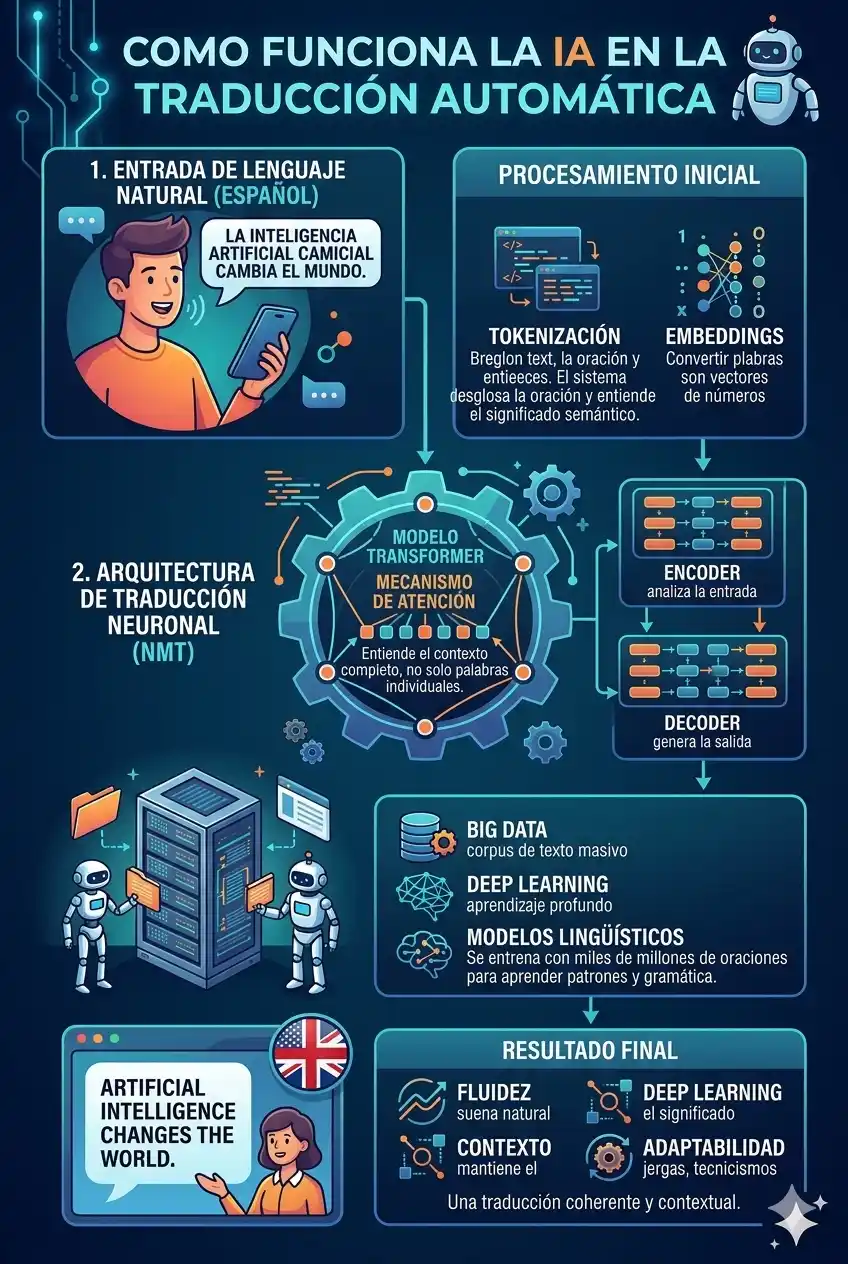
Es la aplicación específica de la IA para convertir texto o habla de un idioma a otro. Ha evolucionado a través de tres etapas técnicas:
- RBMT (Basada en reglas): Utilizaba diccionarios y reglas gramaticales manuales. Era rígida y poco natural.
- SMT (Estadística): Analizaba grandes volúmenes de textos ya traducidos para encontrar probabilidades de equivalencia.
- NMT (Neuronal): El estándar actual. Utiliza redes neuronales profundas para procesar oraciones completas en lugar de palabras aisladas, manteniendo la coherencia y el tono.
3. La Arquitectura Transformer: El Salto Tecnológico
La mayoría de los sistemas modernos (incluyendo traductores avanzados y modelos de chat) se basan en una arquitectura llamada Transformer.
- Mecanismo de Atención: Permite que el modelo «mire» todas las palabras de una oración simultáneamente para entender cuáles están relacionadas. Por ejemplo, en la frase «El banco estaba cerrado porque era tarde», la IA usa la atención para saber si «banco» se refiere a una entidad financiera o a un asiento.
- Codificador y Decodificador: El codificador convierte el idioma de origen en una representación matemática (vector), y el decodificador transforma ese vector al idioma de destino o genera una respuesta lógica.
4. Perspectiva de Implementación
Desde un punto de vista técnico, trabajar con estas tecnologías implica gestionar flujos de datos complejos:
- Embeddings: Representación de palabras en espacios vectoriales multidimensionales donde palabras con significados similares están «cerca» matemáticamente.
- Inferencia: El proceso en el que el modelo ya entrenado recibe una entrada y genera una traducción en milisegundos, optimizado usualmente para correr en GPUs o aceleradores de IA.
- Pipeline de Datos: En entornos Linux, esto suele implicar el uso de librerías como
PyTorchoTensorFlowy la gestión de contenedores para servir los modelos mediante APIs REST o gRPC.